推荐案例
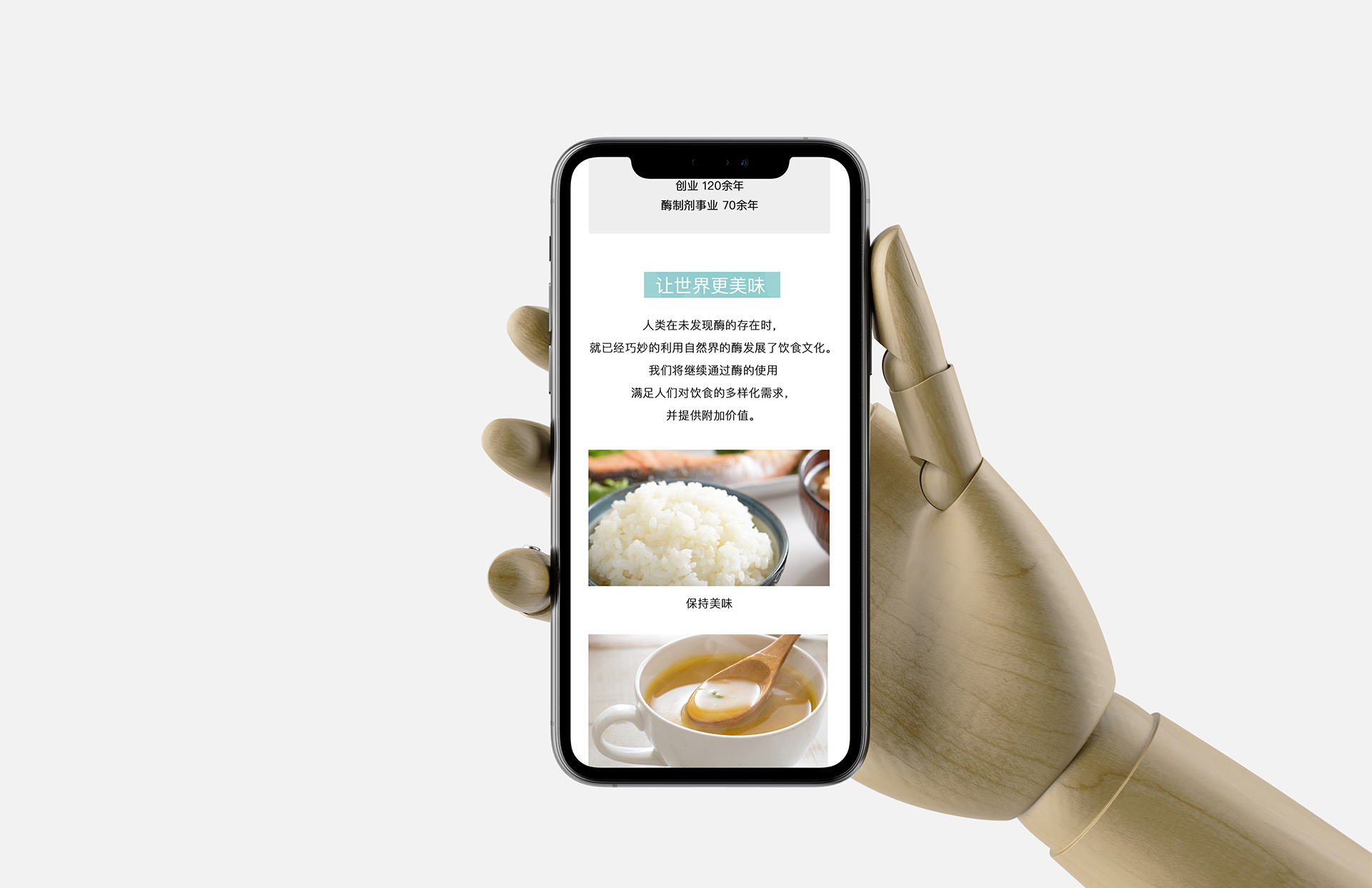
天野酶制剂(江苏)有限公司上海分公司
微信运营
丸梅商贸(上海)有限公司
网站制作
科友贸易(上海)有限公司
网站制作
笑颜股份公司
网站制作
当前位置:首页 > 新闻资讯 > 网站内写了robots协议还可以用熊掌号推送吗怎么正确识别百度蜘蛛
文章来源:常见问题发布时间:2020年11月18日浏览次数:698 views
搜索引擎对网站抓取,内容判断等,仍根据搜索友好度进行判断。近来收到站点反馈,希望加入熊掌号,但是在网站检测中,我们发现,网站内写了robots文件屏蔽百度抓取,这种情况下,百度是无法提取网站内容的;网站推广即便网站通过熊掌号注册来提交数据,百度也无法抓取网站内容。
有一些站点有意或无意中封禁了百度蜘蛛的抓取,导致网站内容无法在百度搜索结果中正常展现。无疑,这样的情况对网站和搜索引擎都非常不利。因此,我们希望网站能够解除对百度蜘蛛的封禁,保证数亿百度用户可以顺利搜索到所需内容,也保证站点可以得到应得的流量。
经常听到站长们问,百度蜘蛛是什么?最近百度蜘蛛来的太频繁服务器抓爆了,最近百度蜘蛛都不来了怎么办,还有很多站点想得到百度蜘蛛的IP段,想把IP加入白名单,但IP不固定,我们无法对外公布。那怎么才能识别正确的百度蜘蛛呢?来来来,只需两步,教你正确识别百度蜘蛛:
1、查看UA,如果UA都不对,可以直接判断非百度搜索的蜘蛛,目前对外公布过的UA是:
移动UA:Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,likeGecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0;+http://www.baidu.com/search/spider.html);PC UA:Mozilla/5.0 (compatible; Baiduspider/2.0;+http://www.baidu.com/search/spider.html)
新增渲染UA:移动UA:Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 likeMac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143Safari/601.1 (compatible; Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)PC UA:Mozilla/5.0 (compatible;Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)
2、反查IP
站长可以通过DNS反查IP的方式判断某只spider是否来自百度搜索引擎。根据平台不同验证方法不同,如linux/windows/os三种平台下的验证方法分别如下:
1、在linux平台下,您可以使用host ip命令反解ip来判断是否来自Baiduspider的抓取。Baiduspider的hostname以 *.baidu.com 或 *.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即为冒充;
2、在windows平台或者IBM OS/2平台下,网站推广您可以使用nslookup ip命令反解ip来 判断是否来自Baiduspider的抓取。打开命令处理器 输入nslookup xxx.xxx.xxx.xxx(IP地 址)就能解析ip, 来判断是否来自Baiduspider的抓取,Baiduspider的hostname以.baidu.com 或.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即为冒充;
3、、 在mac os平台下,您可以使用dig 命令反解ip来 判断是否来自Baiduspider的抓取。打开命令处理器 输入dig xxx.xxx.xxx.xxx(IP地 址)就能解析ip, 来判断是否来自Baiduspider的抓取,Baiduspider的hostname以 .baidu.com 或.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即为冒充。
推荐阅读
推荐案例